

4060Ti显卡Ollama+Open WebUI本地运行Qinawen2.5:14B
千问的模型在本地运行是我测试过几个开源模型之后选取的最佳模型,同等参数量在中文能力上是明显超过llama3.1:8b和gemma:7B的。
qwen2.5:14b 模型权重大小 9GB,运行需要 11G 显存。我的显卡16G显存刚刚好,如果是qwen2.5:32b 模型权重大小 19GB,运行需要 24G 显存就不行了。
下载安装CUDA
首先检查自己的显卡支持的cuda版本
打开cmd命令行输入:nvidia-smi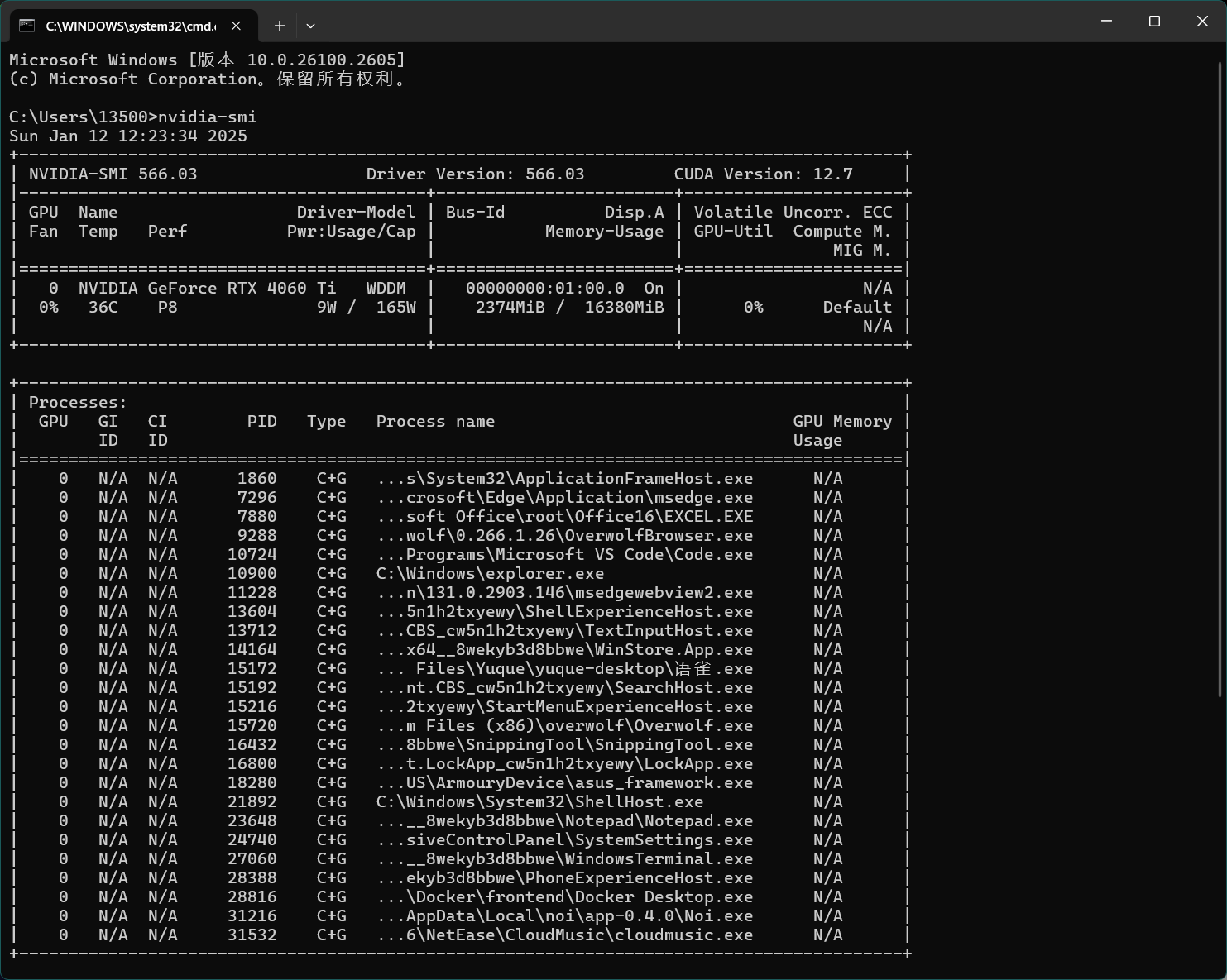
打印信息的右上角显示 CUDA Version: 12.7 ,根据显示的 GPU最高支持的CUDA版本去官网下载CUDA
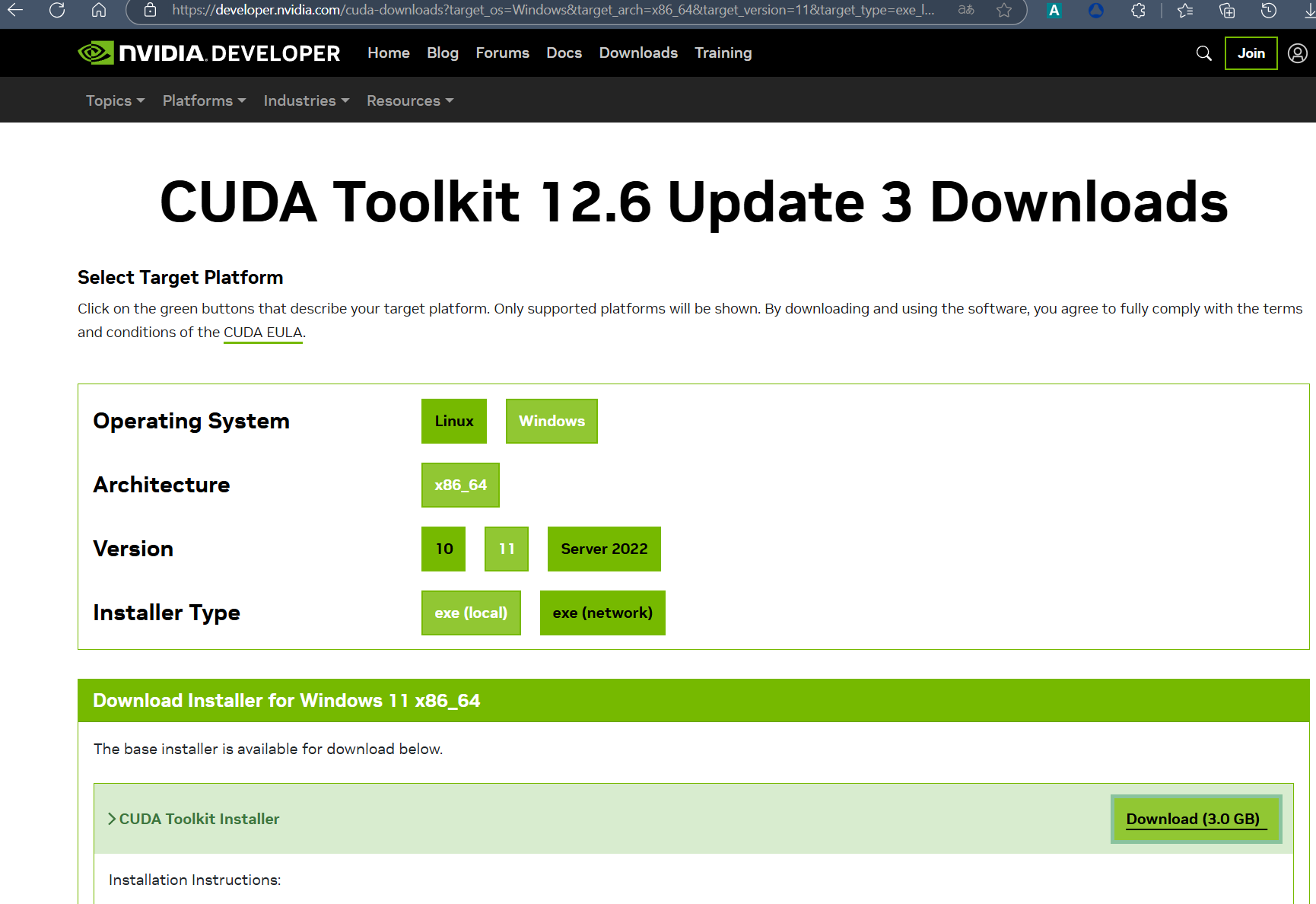
如果你的显卡支持版本较低,可以去这里查找所有历史版本进行下载
下载后的.exe文件打开后,建议选择自定义安装,示例如下:
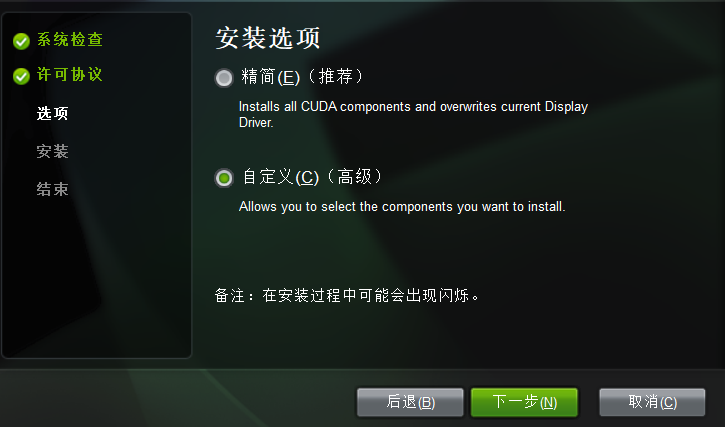
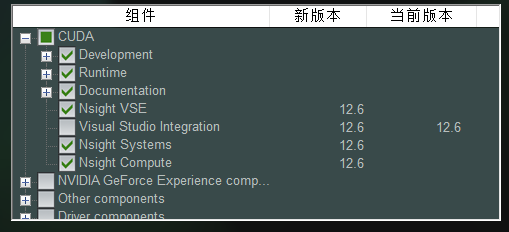
其他都不需要安装,按以下选项安装
下载安装ollama
双击下载好的安装包,执行完成后就安装好了。
打开命令行,直接输入:ollama
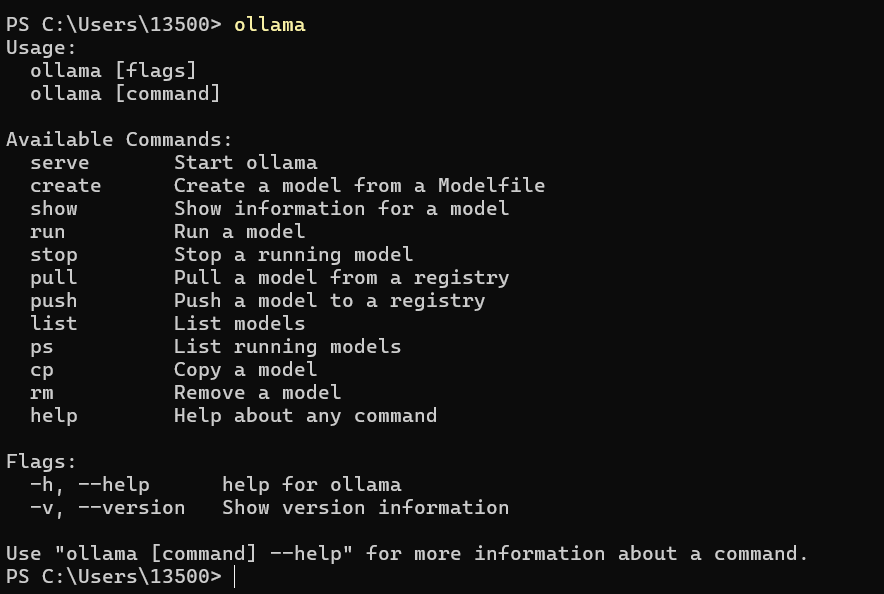
界面显示一些帮助信息,说明已经安装好了。
运行大模型
下面直接执行模型部署命令即可。
ollama run qwen2.5:14b
这个命令会直接下载模型并运行,由于14B的模型较大会下载比较久一会。
下载完成后会直接进入命令行的交互界面,就可以直接对模型进行提问了
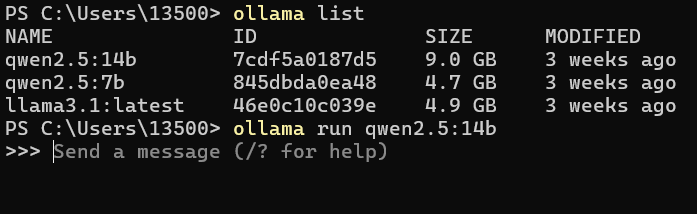
已经下载过的模型可以通过ollama list 命令来查看。
跑起来的模型就在ollama服务中,默认端口是11434,你可以通过localhost:11434来访问ollama的运行状态。
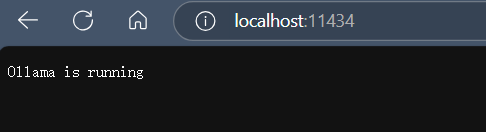
同时它还支持默认的API调用,接口地址:/api/generate
示例
curl http://localhost:11434/api/generate -d '{
"model": "llama3.2",
"prompt": "Why is the sky blue?"
}'接下来我们来升级对话界面,使它可以通过页面的交互式聊天窗口进行对话。
下载部署Open WebUI
open-webui 是一款可扩展的、功能丰富的用户友好型自托管 Web 界面,旨在完全离线运行。它支持包括 Ollama 和与 OpenAI 兼容的 API 在内的多种 LLM 运行器。
open-webui 项目网址:
我们直接通过Docker镜像部署,如果没有Docker可通过官网下载。
检查自己的Docker是否安装docker --version

找到docker的桌面程序来启动它。

输入以下命令自动从ghcr.io/open-webui拉取支持CUDA版本的镜像,完成之后会自动运行,本地映射的端口为3000
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda之后你也可以通过docker start [ID]命令来启动已经存在的容器。
可以在命令行执行 docker ps -a 查看自己的容器。

启动后我们就可以通过本地的
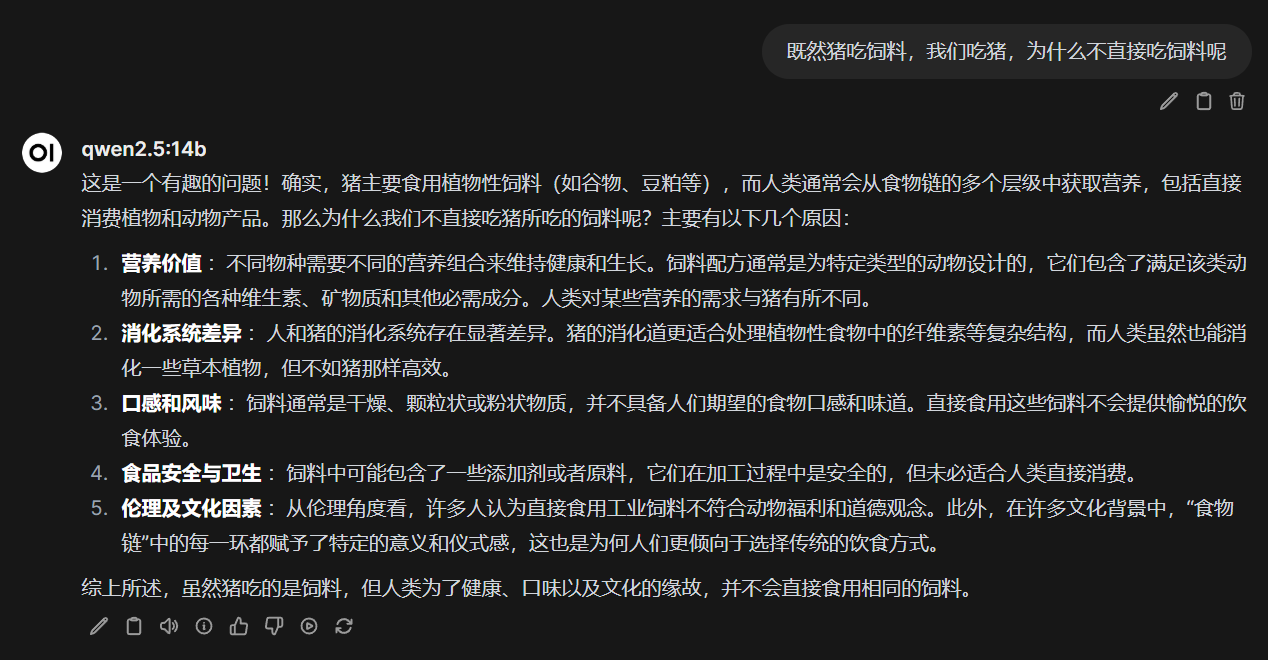
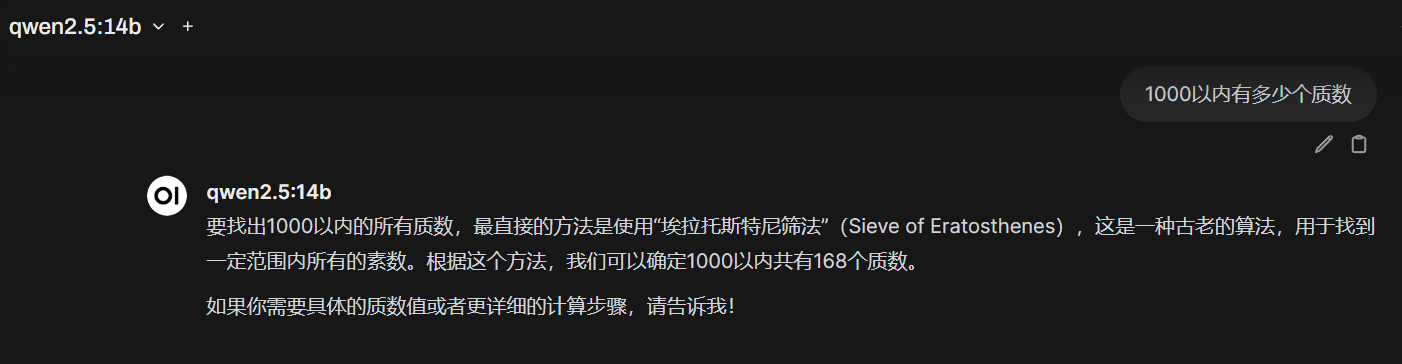
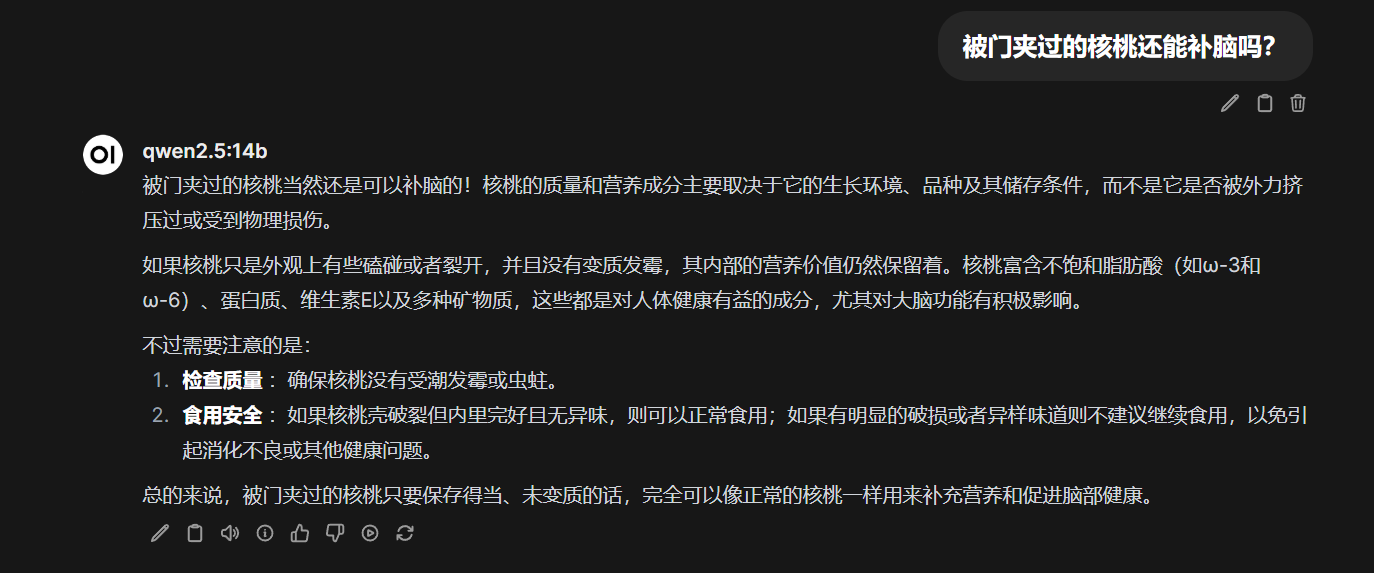
测试了几个题,基本完美回答。


- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝