

基于 MCP(模型上下文协议)的AI 应用客户端交互原理
流程图
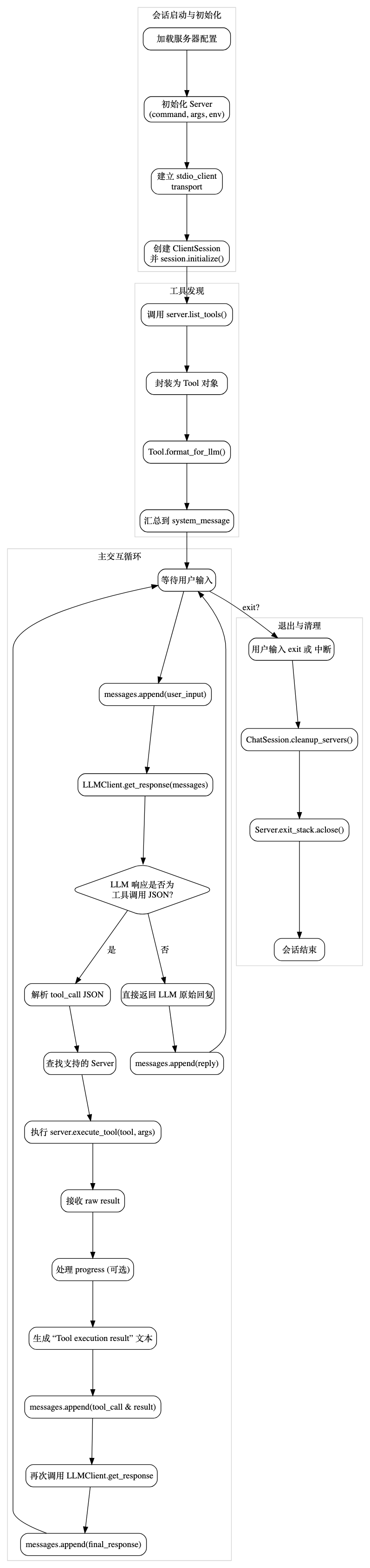
会话启动:加载配置后,为每个 MCP Server 找到命令(如
npx或自定义二进制),通过stdio_client建立底层通信,再创建并初始化ClientSession。工具发现:从各 Server 获取工具列表,封装为
Tool对象,并通过format_for_llm()生成供 LLM 识别的描述文本。主循环:用户输入→LLM 生成回复→若回复为 JSON 格式的工具调用,则执行相应工具并将结果反馈给 LLM 生成最终回复;否则直接返回 LLM 的普通回复。
退出与清理:捕获用户退出或中断信号,依次关闭所有异步资源,保证进程安全终止。
对话记录的上下文构建方式
哪些是用户可见的?自动执行过程中,哪些是用户不可见的?
在这个架构里,所有的「对话记录」——包括用户输入、LLM 的回复、工具调用的请求与返回——都是保存在同一个 messages 列表里,用来喂给 LLM 维持上下文。但在展示给最终用户的时候,通常只会露出用户的输入和 最终 的助手(assistant)回复,中间那些工具调用的 JSON、system 消息之类的“幕后记录”是不直接显示的。
1. 内部消息流(messages 列表)
messages = [ {"role": "system", "content": system_message}, # ① 初始 system:工具列表 + 调用规范 {"role": "user", "content": user_input}, # ② 用户输入 {"role": "assistant", "content": llm_response}, # ③ LLM 原始回复(可能是 JSON) {"role": "system", "content": tool_result}, # ④ 工具执行结果(仅当调用工具时) {"role": "assistant", "content": final_response} # ⑤ LLM 最终回复 # … 后续循环 ]① 初始
system:在会话开始时,注入所有工具的描述和调用规范。② 用户 (
user):每次用户打字都会以{"role":"user"}加入列表。③ 助手初次回复 (
assistant):LLM 根据上下文给出的第一版回答。如果是工具调用,这里就是 JSON 格式。④ 系统反馈 (
system):当检测到工具调用时,框架会执行工具,并把工具的输出结果以{"role":"system"}的形式追加到消息里,作为对 LLM 的“环境补充”。⑤ 助手最终回复 (
assistant):再一次调用 LLM,让它把工具输出整合成自然语言回复,这才是真正回给用户看的内容。
2. 用户能看到 vs. 框架内部
用户界面 只会展示:
用户自己发的内容(
role: user)助手最终给出的回复(
role: assistant,对应上面流程里的 ⑤)
内部
messages列表则同时保存了所有的中间状态,包括工具调用的 JSON 请求、工具执行结果(system)、以及第一次 LLM 的 JSON 响应等。
这样做的好处是:
干净的用户体验 —— 不让用户看到工具调用的底层细节。
完整的上下文追踪 —— 框架能在后续调用中拿到所有历史,包括哪些工具被调用、结果是什么。
工具输出是以哪种角色传给 LLM?
工具执行完毕后,代码是这样插入结果的:
messages.append({"role": "system", "content": tool_execution_result})所以 工具的调用输出是通过 system 角色注入给 LLM,让 LLM 知道「外部世界发生了什么变化/得到了什么数据」,然后它再以 assistant 角色生成最终的自然语言回复。
划重点
合并:所有消息都存在同一个
messages列表里;展示:用户只看得到
user和最后的assistant;工具输出:作为
system消息插入,用于给 LLM 补充上下文。
LLM 在执行工具调用时,如何降低用户等待过程的焦虑感?
工具调用会产生用户等待时长,执行期间产品应该降低用户的焦虑感。我们可以从「反馈及时性」「可预期性」「感知进度」等维度入手:
立即反馈(Immediate Feedback)
在用户发起操作后 0–1 秒内,马上给出视觉反馈(按钮态变化、加载动画等),让用户确信请求已被接收,不会重复点击或中断操作。
对于 1–10 秒的操作,可使用循环动画(indeterminate spinner),以持续告诉用户「系统正在工作」;对于超过 10 秒的操作,最好切换到确定型进度条(determinate progress bar),让用户感知到实际进度。
显示百分比与剩余时间(Percentage + ETA)
如果后端(或工具执行)能返回进度
progress/total,就将它渲染成「已完成 X %」或「预计还需 Y 秒」的文字提示,减少用户对未知时长的担忧。同时配合图形化进度条或分步指示器(例如上传 5/10 文件),让用户对当前状态和接下来要完成的工作量一目了然。
骨架屏与渐进式展示(Skeleton Screens & Streaming)
在等待过程中,先渲染界面骨架(skeleton UI),预先展示页面布局或部分数据框架,让用户「看见」内容在逐步加载,而不是空白或单一的加载图标。
如果可能,使用 LLM 的流式输出(streaming responses),将工具调用结果分块返回给前端,一边加载一边展现,让用户感觉进度在持续推进。
在现有架构中的落地
利用
execute_tool的进度回调:当前execute_tool会返回带progress和total的结构,框架可在每次重试或接收到进度更新时,立即向前端推送一个{"role":"system","content":"进度:XX %"}消息,由 UI 将其渲染为进度条或文字提示。分两步调用 LLM:
第一次调用 LLM 返回工具调用 JSON,紧接着立刻向用户展示「正在处理… 0 %」的占位反馈。
工具执行中持续更新进度;完成后,再把完整结果注入为
system消息,触发第二次 LLM 调用,生成最终回复。
通过「及时→可视→可预期」的分层反馈,就能大幅降低用户在长操作中的焦虑,提升整体体验。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝