

AI 助手应用开发历险记:踩坑指南
我在年初设计了一个智慧园区的 AI 助手产品。上线之后,仅支持文字的对话输入输出。
今年年底,我们决定在原来的基础上增加基于用户上传图片和文档文件的对话功能和智能语音客服。

语音客服的实现方案很简单,就是让用户输入语音,系统自动对音频进行识别,转成文字之后调用大模型 API,大模型输出文字内容后,再通过语音合成模型转成音频自动播放出来。其中用户只觉得是语音对语音的对话,感知不到文字输入输出的过程。
在语音客服的产品设计中,为了实现让大模型实时播放语音,我们采用了流式语音合成大模型,当 AI 生成的文字内容通过实时流的形式传递到前端时,前端实时将文字内容传递给音频合成模型,模型会实时合成语音再返回,在此之中我们发现音频合成返回的音频片段如果直接播放,每个字符之间会有一定的播放延迟,造成机械般的卡顿感,因此我们对音频合成过程传递的每个字词的音频流片段进行了合并,通过句子中的标点符号进行截取,每一个短句合并后转成可播放音频文件片段直接播放,最终实现了无卡顿的实时的流式语音播放。
期间还遇到音频识别的 API 无法正常调用的问题,通过云服务的 key 获取临时密钥的接口重新配置。最终实现了流式音频识别结合流式音频合成播放。
关于图片和文档的识别功能,开发过程中遇到文档无法解析的问题,升级到最新的dify版本,增加了支持文档解析的工具,重新配置了工作流。
但是后续又遇到一个让人摸不着头脑的麻烦。
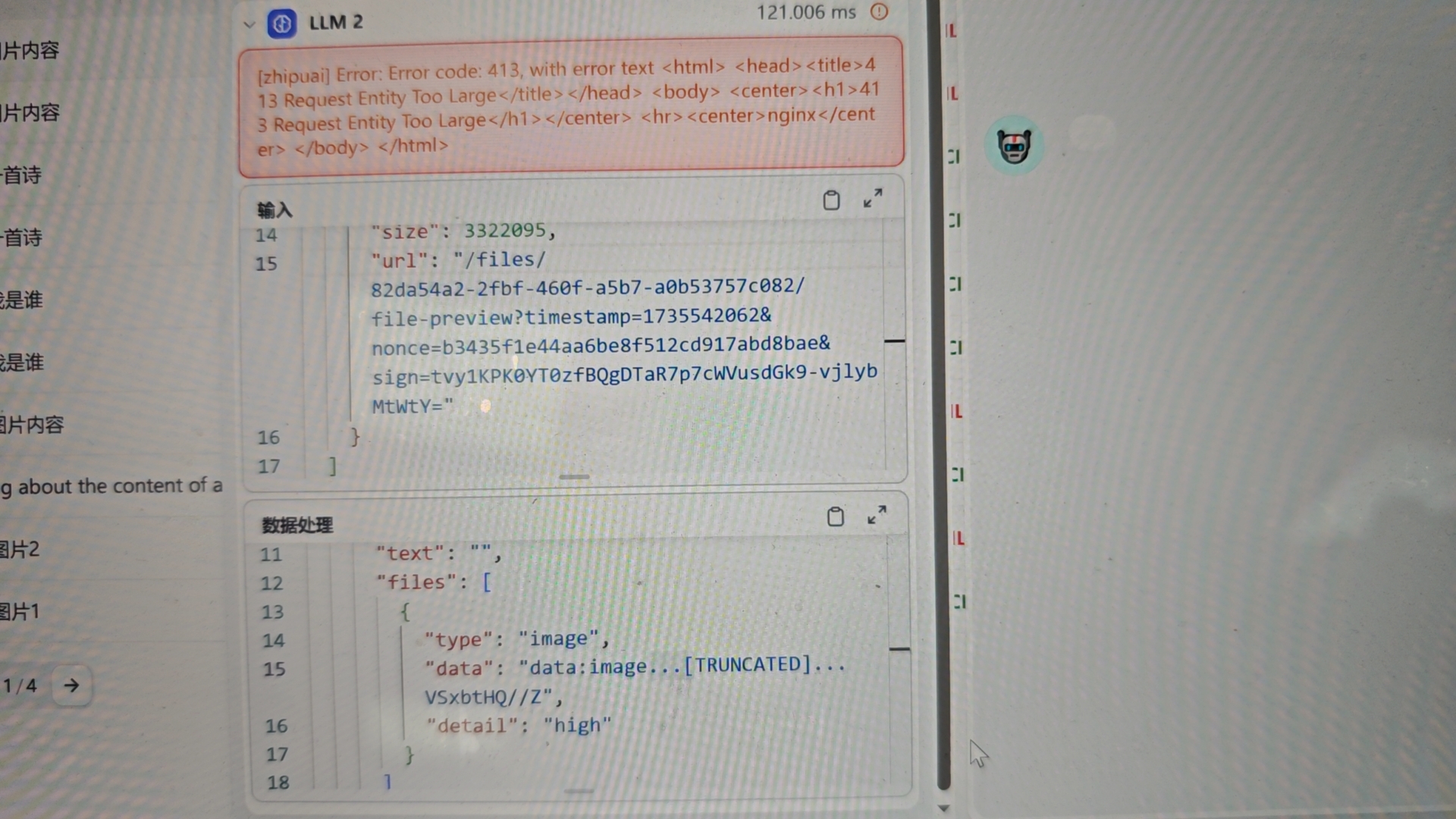
在图片解析开发过程中,遇到了图片上传大小限制的问题,当图片小于 1M 时可以正常回答,超过 1M后提示了请求体超大的 413 错误。经过了 4 天的反复排查,咨询了智谱 AI 的技术人员,查了dify相关请求日志,最终发现问题出在内网服务器对外访问需要经过统一出口,而转发过程要经过两次 Nginx ,对请求的大小进行了限制默认的限制是 1mb。 图片转base64后大小往往是 4/3 倍,所以修改了限制后解决。
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝